Британські фахівці з машинного навчання розробили систему прогнозування майбутніх подій, засновану на концепціях спеціальної теорії відносності: причинності, простору-часу Маньківського і світлових конусах.
Препринт викладений на arXiv.org.
Алгоритм був успішно випробуваний в завданні передбачення і генерації нових кадрів на основі набору зображень. За словами розробників, створений ними підхід універсальний, може застосовуватися для безлічі завдань і буде затребуваний там, де необхідно прогнозування розвитку подій в майбутньому з урахуванням причинно-наслідкових зв'язків, наприклад в області медицини і в автономних транспортних засобах.
Щодня, іноді самі того не помічаючи, ми намагаємося передбачити, як будуть розвиватися події навколо нас. Наприклад, якщо у автомобіля, що рухається перед нами, включений сигнал покажчика повороту, то можна припускати, що він з певною ймовірністю зробить маневр у відповідному напрямку. Однак, автомобіль також може продовжити рух без змін, зупинитися, або повернути в протилежному напрямку.
Ці події вірогідні в більшій чи меншій мірі, і ми можемо очікувати їх, грунтуючись на досвіді взаємодії зі світом і інтуїтивному розумінні законів фізики і причинно-наслідкових зв'язків. З іншого боку, навряд чи ми будемо серйозно розглядати можливість того, що автомобіль раптово зникне, і замість нього на дорозі раптом з'явиться динозавр.
На відміну від людей, у комп'ютерів немає інтуїтивного розуміння причинно-наслідкових зв'язків, тому прогнозування майбутніх подій для них виявляється непростим завданням. При цьому в багатьох областях, де сьогодні відбувається інтенсивне впровадження систем з машинним навчанням, поява такої здатності могла б підвищити рівень безпеки. Наприклад, автомобіль під керуванням автопілота міг би спрогнозувати і оцінити ймовірність того, що дитина, яка стоїть при дорозі, може раптово вибігти на проїжджу частину.
Існуючі підходи до вирішення завдання передбачення майбутнього в машинному навчанні зводяться, наприклад, до тренування моделей на послідовностях кадрів відео. Таким способом алгоритм навчають виявляти закономірності в подіях, які в подальшому можна використовувати для того, щоб згенерувати нові кадри, які раніше не існували кадри і продовжують цю послідовність.
Наприклад, можна показати програмі послідовність кадрів з людиною, яка рухається, а потім попросити її згенерувати наступні кілька кадрів, які б продовжили вихідну послідовність. Однак у підходів, що використовують серії і послідовності кадрів, є схильність швидко накопичувати помилки зі збільшенням числа згенерованих кадрів.
Дослідники під керівництвом Атанасіоса Влонцоса з Імперського коледжу Лондона використовували інший підхід. Вони розробили алгоритм на основі фундаментальних концепцій зі спеціальної теорії відносності (СТО), таких як простір-час і світлові конуси.
В СТО простір-час (або простір Маньківського) являє собою об'єднання тривимірного евклідового простору з четвертим часовим виміром. У такому просторі кожній події можна зіставити точку, просторові координати якої описують місце, де подія відбулася, а тимчасова координата - момент часу, коли воно сталося.
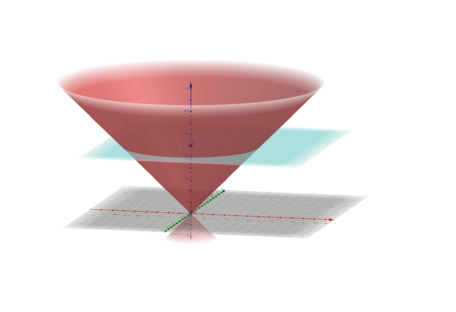
Обмеження на максимально досяжну швидкість поширення сигналів (в СТО це швидкість світла) дозволяє виділити в просторі-часі область, що називається світловим конусом, з центром у вихідній події. Безліч точок всередині виділеної області будуть пов'язані з вихідною подією причинно-наслідковими зв'язками. Так, в конусі майбутнього, що лежить вище вершини (вихідна подія) будуть розташовані всі точки, на які вихідна подія може вплинути, а в нижньому конусі минулого, - події, які могли вплинути на дану подію в вершині. При цьому точки, що знаходяться за межами світлового конуса, не пов'язані причинно-наслідковими зв'язками з вихідною подією.

Фото: перетин світлових конусів (A. Vlontzos et al. / arXiv.org)
Розробники використовували цю концепцію для того, щоб обмежити варіанти можливих нових кадрів, що генеруються їхнім алгоритмом, такими, які близькі за змістом до вихідного зображення і відкинути зображення, що сильно відрізняються від нього.
В якості основи для алгоритму був обраний різновид популярного методу для навчання генеративних моделей - варіаційний автокодувальник Пуанкаре. Зображення, що подаються на вхід, перетворюються енкодером в уявлення в прихованому просторі, яке має властивості простору Маньківського з вісьмома просторовими і одним тимчасовим вимірами.
Така розмірність простору була обрана як оптимальна експериментальним шляхом. Потім алгоритм будує світлові конуси навколо цих точок і шукає їх перетин для того, щоб виділити ту частину прихованого простору, в якій можуть знаходитися майбутні (або минулі, в нижньому конусі) кадри. Схожі за змістом кадри виявляються недалеко один від одного. Надалі виробляючи вибірку з цього підпростору можна намагатися прогнозувати майбутні кадри.
У якості наборів даних для навчання моделі дослідники використовували модифікований набір moving MNIST, що складається з невеликих фрагментів відео з рукописними цифрами, що переміщаються. Кожен фрагмент являє собою послідовність з 30 кадрів.
Всього було використано 10 тисяч фрагментів з цього набору. Крім того, розробники використовували набір даних KTH action recognition dataset, що складається з коротких відеокліпів, які демонструють руху людей, наприклад ходьбу або помахи руками.
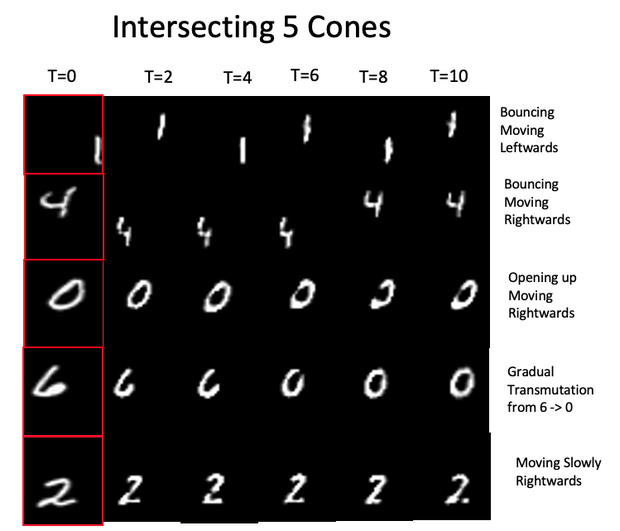
Фото: результати згенерованих кадрів на основі датасета MNIST, в залежності від часу (A. Vlontzos et al. / arXiv.org)
Потім дослідники доручили алгоритму генерацію безлічі потенційно можливих кадрів на основі вхідного одиночного тестового кадру. Незважаючи на те, що в вагах нейромережі відсутня тимчасова інформація, так як навчання проходило на сукупності окремих кадрів, а не їх послідовності, виявилося, що алгоритм здатний прогнозувати відповідні майбутні можливі кадри.
Наприклад, якщо на вхід подається кадр, на якому зображений людина з коротким волоссям і в сорочці, яка йде, то алгоритм генерує найбільш підходящі кадри, на яких зображена така ж людина, і відкидає кадри, що сильно відрізняються, наприклад, з людьми з довгим волоссям або без сорочки.
Як стверджують автори дослідження, розроблений ними алгоритм не схильний до ефекту накопичення помилок, так як він не покладається на здатність нейронних мереж витягувати і запам'ятовувати структурну і тимчасову інформацію з оброблюваних зображень. На даний момент діаметр конуса вибирається вручну і вважається фіксованим, що означає постійну швидкість еволюції для всіх кадрів і конусів. Однак в реальності ці швидкості можуть бути різними. У майбутньому дослідники планують впровадити автоматичне підстроювання діаметрів світлових конусів.
Алгоритм може використовуватися в областях, де потрібно прогнозування можливих варіантів розвитку подій. Наприклад, крім застосування в автопілотах для підвищення безпеки автономних транспортних засобів, новий підхід може бути використаний в медицині для прогнозування того, як лікарські препарати будуть впливати на стан пацієнта, або як буде прогресувати захворювання на підставі даних знімків МРТ і призначуваного лікування.
Як повідомляв Realist, австралійська Комісія з майбутнього людства, яка складається з провідних вчених і громадських активістів, назвала 10 головних загроз для виживання людства.






