Британские специалисты по машинному обучению разработали систему прогнозирования будущих событий, основанную на концепциях специальной теории относительности: причинности, пространства-времени Минковского и световых конусах.
Препринт выложен на arXiv.org.
Алгоритм был успешно испытан в задаче предсказания и генерации новых кадров на основе набора изображений. По словам разработчиков созданный ими подход универсален, может применяться для множества задач и будет востребован там, где необходимо прогнозирование развития событий в будущем с учетом причинно-следственных связей, например в области медицины и в автономных транспортных средствах.
Ежедневно, иногда сами того не замечая, мы пытаемся предсказать как будут развиваться события вокруг нас. Например, если у двигающегося перед нами автомобиля включен сигнал указателя поворота, то можно предполагать, что он с определенной вероятностью совершит маневр в соответствующем направлении. Однако, автомобиль также может продолжить движение без изменений, остановиться, или повернуть в противоположную указываемому направлению сторону. Эти события вероятны в большей или меньшей степени, и мы можем ожидать их, основываясь на опыте взаимодействия с миром и интуитивном понимании законов физики и причинно-следственных связей. С другой стороны, вряд ли мы будем всерьез рассматривать возможность того, что автомобиль внезапно исчезнет, и вместо него на дороге вдруг появится динозавр.
В отличие от людей, у компьютеров нет интуитивного понимания причинно-следственных связей, поэтому прогнозирование будущих событий для них оказывается непростой задачей. При этом во многих областях, где сегодня происходит интенсивное внедрение систем с машинным обучением, появление такой способности могло бы повысить уровень безопасности. Например, автомобиль под управлением автопилота мог бы спрогнозировать и оценить вероятность того, что стоящий у дороги ребенок может внезапно выбежать на проезжую часть.
Существующие подходы к решению задачи предсказания будущего в машинном обучении сводятся, например, к тренировке моделей на последовательностях кадров видео. Таким способом алгоритм обучают выявлять закономерности в событиях, которые в дальнейшем можно использовать для того, чтобы сгенерировать новые, ранее не существовавшие кадры, продолжающие эту последовательность.
Например, можно показать программе последовательность кадров с двигающимся человеком, а затем попросить ее сгенерировать следующие несколько кадров, которые бы продолжили исходную последовательность. Однако у подходов, использующих серии и последовательности кадров, есть склонность быстро накапливать ошибки с увеличением числа сгенерированных кадров.
Исследователи под руководством Атанасиоса Влонцоса (Athanasios Vlontzos) из Имперского колледжа Лондона использовали иной подход. Они разработали алгоритм на основе фундаментальных концепций из специальной теории относительности (СТО), таких как пространство-время и световые конусы.
В СТО пространство-время (или пространство Минковского) представляет собой объединение трехмерного евклидова пространства с четвертым временны́м измерением. В таком пространстве каждому событию можно сопоставить точку, пространственные координаты которой описывают место, где событие произошло, а временна́я координата — момент времени, когда оно случилось.
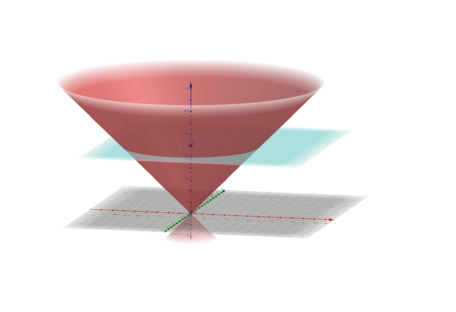
Ограничение на максимально достижимую скорость распространения сигналов (в СТО это скорость света) позволяет выделить в пространстве-времени область, называемую световым конусом, с центром в исходном событии. Множество точек внутри выделенной области будет связано с исходным событием причинно-следственными связями. Так, в конусе будущего, лежащем выше вершины (исходное событие) будут расположены все точки, на которые исходное событие может повлиять, а в нижнем конусе прошлого, — события, которые могли повлиять на рассматриваемое событие в вершине. При этом точки, находящиеся за пределами светового конуса, не связаны причинно-следственными связями с исходным событием.

Фото: пересечение световых конусов (A. Vlontzos et al. / arXiv.org)
Разработчики использовали эту концепцию для того, чтобы ограничить варианты возможных новых кадров, генерируемых их алгоритмом, такими, которые близки по содержанию к исходному изображению и отбросить изображения, сильно отличающиеся от него. В качестве основы для алгоритма была выбрана разновидность популярного метода для обучения генеративных моделей — вариационный автокодировщик Пуанкаре. Подаваемые на вход изображения преобразуются энкодером в представление в скрытом пространстве, которое обладает свойствами пространства Минковского с восемью пространственными и одним временным измерениями.
Такая размерность пространства была выбрана как оптимальная экспериментальным путем. Затем алгоритм строит световые конусы вокруг этих точек и ищет их пересечение для того, чтобы выделить ту часть скрытого пространства, в которой могут находиться будущие (или прошлые, в нижнем конусе) кадры. Похожие по содержанию кадры оказываются недалеко друг от друга. В дальнейшем производя выборку из этого подпространства можно пытаться предсказывать будущие кадры.
В качестве наборов данных для обучения модели исследователи использовали модифицированный набор moving MNIST, состоящий из небольших фрагментов видео с перемещающимися рукописными цифрами. Каждый фрагмент представляет собой последовательность из 30 кадров.
Всего было использовано 10 000 фрагментов из этого набора. Кроме того, разработчики использовали набор данных KTH action recognition dataset, состоящий из коротких видеоклипов, демонстрирующих движения людей, например ходьбу или взмахи руками.
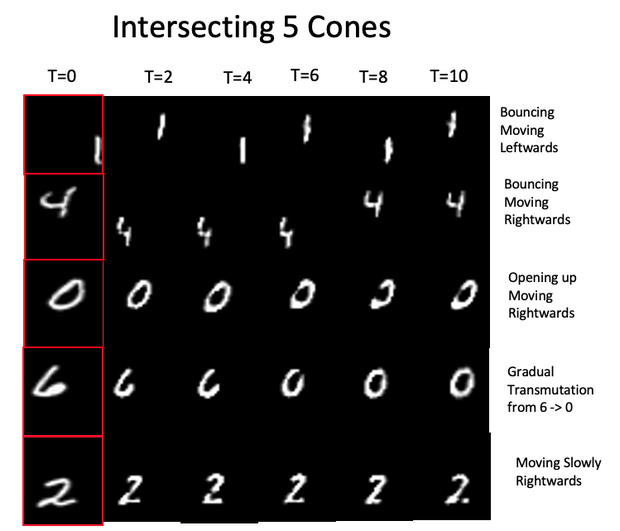
Фото: результаты сгенерированных кадров на основе датасета MNIST, в зависимости от времени (A. Vlontzos et al. / arXiv.org)
Затем исследователи поручили алгоритму генерацию множества потенциально возможных кадров на основе входного одиночного тестового кадра. Несмотря на то, что в весах нейросети отсутствует временна́я информация, так как обучение проходило на совокупности отдельных кадров, а не их последовательностях, оказалось, что алгоритм способен прогнозировать подходящие будущие возможные кадры. Например, если на вход подается кадр, на котором изображен идущий человек с короткими волосами и в рубашке, то алгоритм генерирует наиболее подходящие кадры, на которых изображен такой же человек, и отбрасывает сильно отличающиеся кадры, например с людьми с длинными волосами или без рубашки.
Как утверждают авторы исследования, разработанный ими алгоритм не подвержен эффекту накопления ошибок, так как он не полагается на способность нейронных сетей извлекать и запоминать структурную и временную информацию из обрабатываемых изображений. На данный момент диаметр конуса выбирается вручную и считается фиксированным, что означает постоянную скорость эволюции для всех кадров и конусов. Однако в реальности эти скорости могут быть разными. В будущем исследователи планируют внедрить автоматическую подстройку диаметров световых конусов.
Алгоритм может использоваться в областях, где требуется прогнозирование возможных вариантов развития событий. Например, помимо применения в автопилотах для повышения безопасности автономных транспортных средств, новый подход может быть использован в медицине для прогнозирования того, как лекарственные препараты будут воздействовать на состояние пациента, или как будет прогрессировать заболевание на основании данных снимков МРТ и назначаемого лечения.
Как сообщал Realist, австралийская Комиссия по будущему человечества, которая состоит из ведущих ученых и гражданских активистов, назвала 10 главных угроз для выживания человечества.






